アカツキの夏インターンシップで生まれた2つの成果とそこから得られた知見
はじめに
こんにちは。task4233です。
7/19~8/6 の3週間、株式会社アカツキの基盤開発等を行っているATLASチームにて、インターンシップに参加させていただきました。
そこで、私は下記の2つの成果を生むことが出来ました。
- APIの設計と実装
- パフォーマンスの検証と改善
この記事では、関わったサービスの紹介をした上で、私が取り組んだ内容とそこから得た知見を紹介し、最後にインターンシップ全体を通して良かったと感じたことを書きます。
もくじ
ゲーム内通貨管理サービス
このサービスの構成は下記の通りでした。

本体のゲーム内通貨管理サーバはGoで実装されており、本番環境ではApp Engine上で稼働しています。このサーバが各ゲームサーバに対してAPIを提供することで、ゲーム内通貨の管理をゲーム内通貨管理サーバに集約することが可能です。更に、管理されているゲーム内通貨はFlaskで実装された管理画面からも操作することも可能です。この操作権限を管理するために、権限を3段階に分けてAPI KEYとして利用者に提供しています。
また、ゲーム内通貨管理サーバは、権限を管理するための鍵を保持するSecret Manager、データを管理するDatastore、データ解析用のBigQueryを利用しています。
1.APIの設計と実装
まず、私はSecret Managerで管理している鍵のキーローテーション用APIの設計と実装に取り組みました。
キーローテーションとは、新たなバージョンの鍵を発行して古い鍵を失効させる仕組みです。これにより、セキュリティ強化が見込めます。
キーローテーションは手動で行うことも可能です。しかし、ゲームサーバが利用中の鍵を、誤って失効させるようなヒューマンエラーを防止するため、このAPIを設計および実装することになりました。
このAPIの設計と実装は、
- Swaggerの定義を書く
- 各エンドポイントの仕様について議論する
- 実装する
- レビューを通して実装を修正する
という順序で進め、設計と実装はサクッと終わりました。
サクッと実装できたのは、既存の実装が層ごとに責務が分割されていたためだと考えています。
既存の実装はコントローラ層、インフラ層、ドメイン層に分けられており、コントローラ層は受け取ったリクエストのハンドリング、ドメイン層はロジック、インフラ層では永続化と再構成といった責務の分割が為されていました。そのため、私は既存のコードを参考にしつつ、ロジックのユニットテストと全体のインテグレーションテストを書いて実装することが出来ました。
そのテスト中にPCが重くなることが何度かありました。原因を調査したところ、Datastoreのエミュレータがテスト後にゾンビ化していたことが判明しました。これに気づいた時に、Connectionが閉じられていないのでは?と思い、実際のコードを見るとClose処理が全くありませんでした。
ConnectionをCloseしないとディスクリプタを消費し続けるので、結果的にリソースの圧迫に繋がります。DatastoreのGodocには、下記の通り「終わったら閉じろ」と書かれていました。
Call Close to clean up resources when done with the client
しかし、GoのGCがよしなにコネクションを解放している可能性も否定できませんでした。
そこで、実際に負荷試験を用いてCloseがパフォーマンスに及ぼす影響を定量的に判断することにしました。
2. パフォーマンスの検証と改善
チーム内に既に負荷試験を実施していた方がいたため、その方と話しあいながら負荷試験を設計しました。その方曰く、負荷試験で大事なのは、遅くなりそうな場所を予測して、その特定の場所に的を絞って計測することとのことでした。そのため、調査したかったDatastoreのClientが持つConnectionの生成を行うハンドラについて、Close有/無の場合で2回負荷試験を行いました。
その時の負荷試験は下記の通りPR上で計画しました。


今回の負荷試験はLocustを用いました。選定理由は、チーム内で既に行われていたのがLocustを用いた負荷試験だったためです。この検証を始めたのがインターンシップ終了5日前だったので、つまらない部分で躓かないように選定しました。
検証環境はLocustを動かすためにGKEを用い、検証対象サーバはGoを動かすためにApp Engineを利用しました。 そして、LocustのWorkersから1000RPS*1〜5000RPS程度飛ばしました。 この値に設定したのは、今回のテストがConnectionの生成のみをテスト対象としたためです。 全体の負荷試験を行う場合は、そのサービスのSLOを満たすレベルの負荷試験を行うと良いそうです。
さて、話を戻すと、行った負荷試験の結果がこちらです。
Closeあり


Closeなし


この結果から、下記の事実確認と考察が出来ました。
- Closeを行うことで500エラーは100%減(22->0)
- 500エラーの原因はGCPのログからメモリ枯渇と判明
- 平均応答時間は40%増(95[ms]->133[ms])
- 新たにClose処理を加えたためと考えられる
- 4000RPS付近からCloseの有無に関わらずレイテンシが増加
- Close以外の部分がボトルネックになっていると考えられる
4000RPS付近からレイテンシが高くなっていた原因の調査
この原因となっているボトルネックを調査するために、ハンドラにトレースを入れて再度負荷試験を実施しました。
その結果、レイテンシが高い時のトレースと低い時のトレースで、インスタンスであるcontainerのCreateにかかる時間に大きな差があることが分かりました。
そこで、このCreateの実装を確認すると下記の2つの操作が行われていました。
- 新たなClientの作成
- middlewareの挿入
middlewareの挿入は、内部的にスライスに対するappend処理のみを行なっていたため重くない処理と判断し、更に新たなClientの作成の実装を確認しました。
そこでは、
- Google CloudのライブラリでgRPCクライアントを生成する処理
- mercari.ioのライブラリでそのクライアントをラップする処理
が行われていました。後者は型変換が行われていただけなので、前者が重くなる処理と結論づけました。
ClientPoolの実装によるパフォーマンスの改善
この重くなる処理と考えられる処理を軽くするために、このgRPCクライアントをプールすることにしました。gRPCの通信はステートレスな通信なのでプール出来ないと思っていたのですが、データの送受信がない時も関係のないデータを流し続けることで再利用ができるようです。賢いですね。
余談ですが、gRPCのコネクションプールは下記のコードがシンプルで良さそうでした。
使えることがわかったため、実装をして再度ClientPoolを利用する場合としない場合で再検証を行いました。
その結果は下記の通りです。
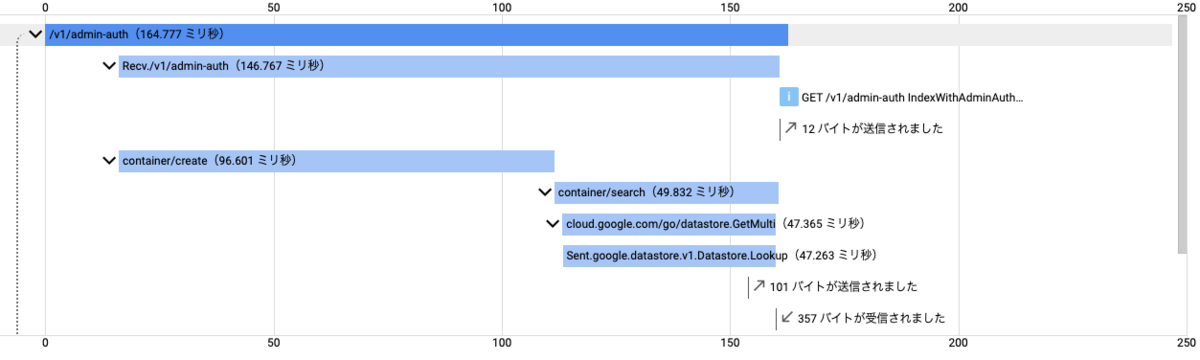
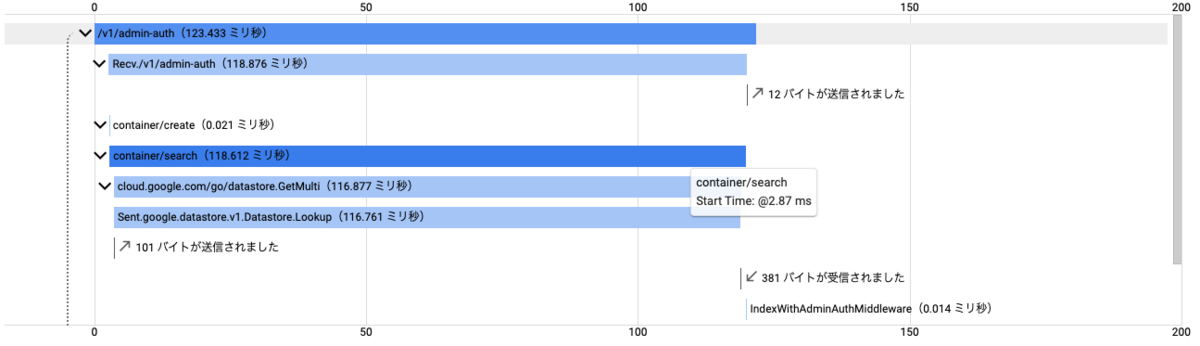
この結果から、クライアントをプールすることで平均応答時間は26%減(133[ms]->105[ms])になっていることが分かります。したがって、クライアントをプールすることでパフォーマンス改善に繋がりました。
以上が、インターン中に行なったパフォーマンスの検証と改善です。
学べたこと
学べたことは大きく分けて2つです。
1つ目は、機能を適切な層に分割して実装することで、可読性とテスト設計のしやすさが高くなるということです。
これは、新しく大規模なソースコードに触れたからこそ、設計を意識した実装の重要さを再認識することが出来ました。
2つ目は、ボトルネックを調査して改善するまでのフローを経験できたことです。
私は本インターンで経験するまで負荷試験を行ったことがありませんでした。そのため、ボトルネックを予測と計測を組み合わせて発見し、それを改善する経験ができたのは大きな学びにつながりました。
メンターさんの:+1:ムーブ
これは余談ですが、今回のインターンシップで、なかひこさんにメンターとして様々な面で助力いただきました。なかひこさんが実施してくださったものの中で、ありがたかったことを列挙しておきます。
- 1on1ミーティングを毎日実施してくださったこと
- 毎日相談できる時間が保証されるのは心理的に良かったです
- 細部まで丁寧にPRのレビューをしてくださったこと
- 「なぜそうしたのか」という部分まで突き詰めてくださったのが良かったです
- 1エンジニアとして扱ってくださったこと
- 「これをやってみたい」と提案したことに対して全てYESで返すのではなく、必要性を議論しながら進められたのが良かったです
このような経験ができたのは、ひとえにメンターのなかひこさんとATLASチームの皆さんのおかげです。本当にありがとうございました。
おわりに
今回のインターンシップを通して、開発中のプロダクトに触れることで気づけた設計の重要性と、負荷試験の流れを経験しながら学ぶことが出来ました。
このインターンシップで得られた知見は、今後の開発で十分生かせると思います。
今回、良いインターンシップになるように尽力してくださったアカツキの皆さんには本当に感謝しています。 ありがとうございました!
*1:Request per Seconds